Last July I joined Nector to build a customer facing voice agent for ecommerce (search, orders handled through voice instead of browsing a website).
Correctness and speed are non negotiable in these products, with a high bar for user experience, and I got a lot to learn from the experience.
This post shows a bit of what I built at Nector, what I learnt and how I’m taking things forward.
Background
This was a new product, separate from Nector’s core business of customer retention. I got to design parts of the system, drive the product’s growth and changes to improve user experience and other goals, and it’s been a tremendous learning experience.
As part of the transactional side of things I got to work on building multi tenant backend systems, integrating multiple third party services, working with MCPs, observability and database design.
Problems I got to solve (what I built)
While I can’t go into detail as it’s IP of the org, there’s a few interesting things I’d like to share.
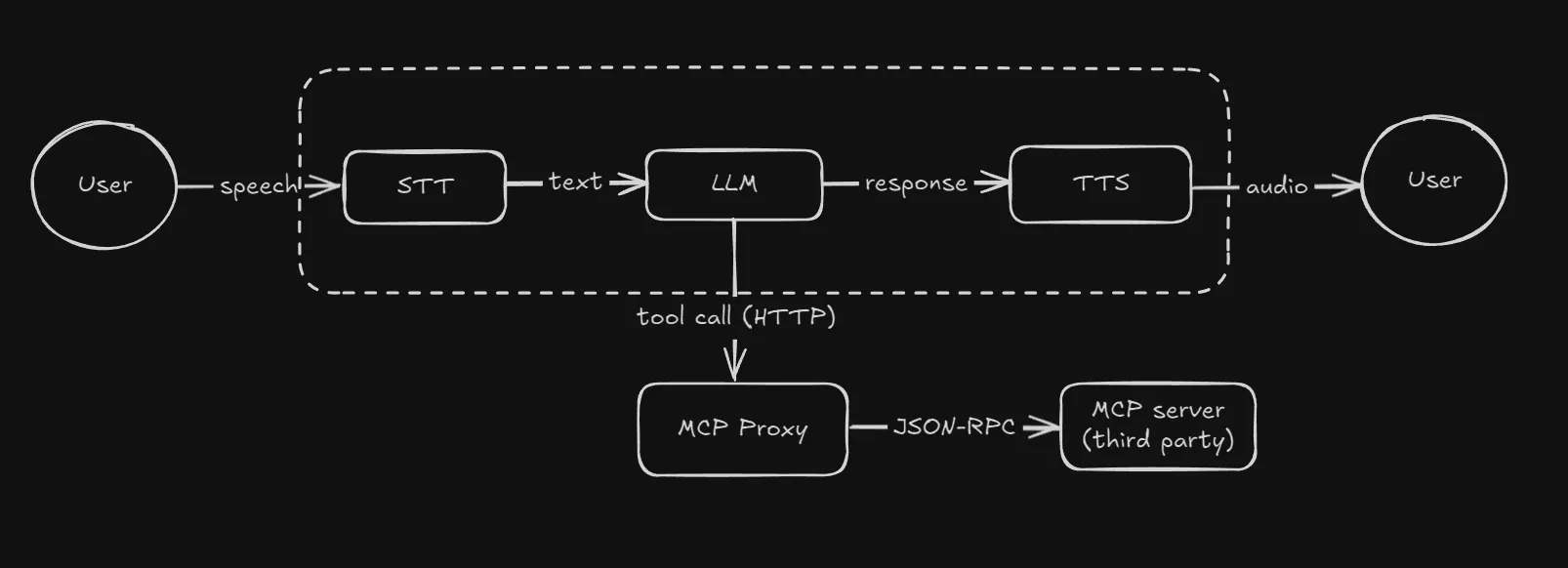
MCP proxy
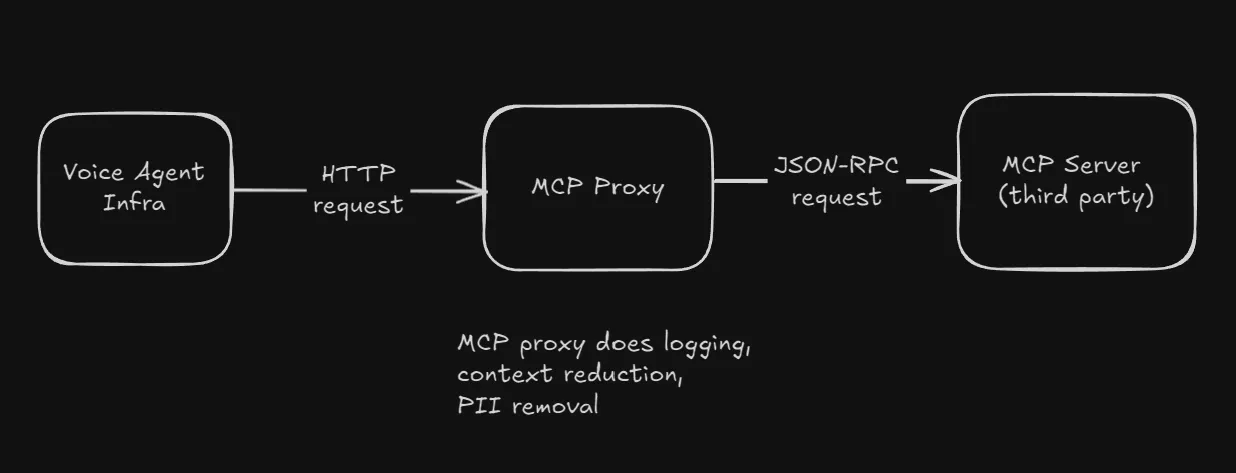
For the transactional part we integrated a third party service with the voice agent infra through MCP. The problem was that we had two opaque systems now, and we did not know the cause of errors in MCP calls, which were happening on almost all tool calls.
We were considering abandoning MCP and switching to building our own tools over APIs, but before we did that I tried building a proxy that converted REST API calls to JSON-RPC and passed it on to the MCP.
This gave us observability and allowed us to fix issues easily (this particular one stemmed from the agent platform passing in a ton of data along with the MCP request).
Later on this also provided us with data control (PII removal) and context reduction, through which latency and correctness improved a lot.
MCP proxy
Latency optimization
We built a lot of voice agents, and one of these was facing extremely high latencies, p90 was crossing 8 seconds. This was extremely unacceptable, users would end the call if there was no response for such a long time. We tried to figure out the issues which were making this agent behave this way, doing a lot of experiments to figure out which combination of models, VAD settings, tool call paths etc. were causing the issue.
Ultimately a combination of the above and a much improved context in the prompt brought down the p90 to 2 seconds, which was a major improvement and acceptable for a customer facing product.
The results from these experiments were applied to other agents, and we did not face similar issues in them.
Markdown formatting in voice agents
This one’s my favorite bug, which took way more time to fix than expected.
The MCP that we were using was built for text based agents, to be used on visual user interfaces. It contained a lot of content in markdown format, and specific instructions to the agent on how to render this.
The problem was that we were doing voice agents, and the agent was literally rendering the outputs as markdown (for example - saying out things in a numbered list like 1. item 1, 2. item 2).
The MCP proxy I built before helped fix this, by filtering out content that was causing these issues. Some more prompt changes and things worked out exactly as expected.
Correctness
Transactional systems need to be correct. Grounding non-deterministic voice agents in transactional systems is difficult, which includes ensuring tool calls happen exactly when needed, hallucination reduction and doing tons of testing.
This took a lot of trial and error, a ton of prompt updates, especially to ensure the tool calls happened when expected, happened with the exact format expected by the graphql APIs, especially with evolving understanding of how we wanted a particular user action to happen.
What I learnt
Product thinking
Starting out with just concepts of what we were trying to build, I got the chance to learn how to think what the users need, how they would be experiencing things and using these ideas to build requirements for the core voice agent and later improve the user experience.
This part helped us include important functional requirements that we iteratively built upon as the product progressed, and was the most valuable thing that I took away from this internship
New tech
Cloudflare, NodeJS, GraphQL
Prior to this I hadn’t used any of these. A lot of the work in implementing the backend systems required were supplemented by AI, with rigorous reviews and refactoring for maintainability. Still, I learnt enough to write a few APIs, webhooks and database logic on my own.
The greatest challenge was working with the Cloudflare ecosystem. Workers is extremely minimal, so most libraries don’t work, and you need creative ways to solve problems. A lot of the features cloudflare provides were incredibly helpful while building this, and the limitations made working around them even more fun.
A lot of new models also dropped in the LLM and TTS space since the last time I built voice agents (prev internship at Qlink), and I was astonished to see how far this industry had come. Nevertheless, speed vs quality tradeoffs remained similar to before, GPT5 was a powerful model but had terrible latency, also tended to say a lot. I found (yet again) GPT 4o to be a pretty good model for the task at hand, which is why I’m sad to see it go. We couldn’t get better models for TTS and STT, due to the restrictions with the service we were using and that limited the results.
Buy vs Build
Early on we were faced with the decision of whether to subscribe to third party services or build and deploy our own solution for the voice agent infrastructure.
We decided to go with using a service for this part instead of building our own, prioritizing development of the product over owning the whole stack from day 1. This sped things up immensely, however it had its downsides too, which gave us important lessons for what to include (and more importantly, what we shouldn’t do) while building our own infra. A lot of the work in this product was integrations.
Multi tenancy
I had already seen a bit of this in Mimir, however building a multi tenant system from scratch is completely different. A lot of database design considerations, concurrency and checks had to be applied, and I got to learn a lot.
Apart from this I got to work with feature flags, cron and webhooks in this multi tenant context, which was interesting.
What I’d do differently
I think I wrote a ton of docs (as it was an exploratory project). Nevertheless I still documented much less than I should have, and I’d be more intense in doing this.
I’d also work more on observability. This was something I don’t understand that well, yet it’s crucial for finding errors and debugging. Reading logging sucks helped me understand the kind of observability we should have done.
I’d try making the infra part myself around month 4, which would solve a lot of the pain we felt with Retell - unannounced feature deprecation, price changes, fragmented docs etc.
I’d push to involve domain experts at an earlier stage. This is the single thing that could have taken this product from good to great, and would bridge the knowledge gaps that I couldn’t fill in.
I’d keep doing experiments to optimize latency, automate more of the workflow we used, enable clarity and make things easier for everyone to contribute and understand.
Culture
Nector’s engineering culture is something I have a deep respect for and I try to look for parts of this whenever I’m evaluating a company.
They’ve got a relentless focus on the business side of things, and obsess on providing business value and improving user experience. Tech is built to support these ideas, based on what the business needs now.
The simplicity and clarity of how they work is something I strive to emulate.
What next
I’ve been exploring observability, databases and concurrency (through personal projects - checkout github).
I’m writing a post on how to build good voice agent products, which I expect to be out in April.
I’m also looking for opportunities, full time or otherwise, in backend oriented roles. Reach out if you’ve got something in mind.